One of the Best Research papers of 2022: Constitutional AI, Training LLMs Using Principles
Let’s understand CAI and who uses it:
Claude is a next-generation AI assistant based on Anthropic’s research into training helpful, honest, and harmless AI systems. This involves utilizing AI feedback instead of human feedback to “reflect” on the generated text output during training.
The difference between ChatGPT and Claude is ChatGPT uses RLHF(The RL model is trained using quality ratings provided by humans) whereas Claude uses RLAIF (Reinforcement Learning from Artificial Intelligence Feedback). Anthropic train the model with a technique known as “Constitutional AI” (CAI), which relies less on human feedback and more on AI Feedback.
The author’s method of self-supervised approach to AI safety, Alignment, and proper use of LLM by making it more efficient, transparent, and targeted is really an impactful idea and with its better applications in the coming days. This method of critiquing in the SL stage, and for evaluating comparisons for the RL stage has improved focus and performance, making feedback more transparent, interpretable, and improveable.
First, let’s understand about Constitution:
Basically, It is a body of fundamental principles or established precedents according to which a state or other organization is acknowledged to be governed.
In the same way, in this paper, a method known as Constitutional AI (CAI), is a small set of principles that is used to train a non-evasive and relatively harmless AI assistant, without any human feedback labels.
The main goal of the authors is
1. To train a helpful and harmless assistant that is never evasive, in order to reduce the tension between helpfulness and harmlessness.
2. Assistant must refrain from helping users with unethical requests, and from expressing offensive language and sentiment
3. It should always engage and explain why it refuses such requests.
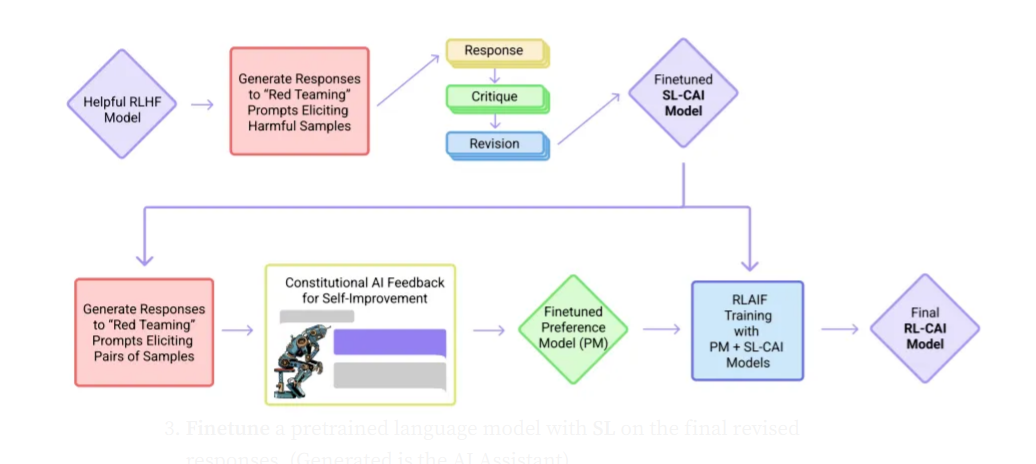
The Constitutional AI (CAI) method involved 2 phases
1: Supervised learning(SL) Phase
2: Reinforcement learning(RL) Phase
In the Supervised learning (SL) Phase
( Critique → Revision → Supervised Learning )
1: Generate responses to harmfulness prompts using a helpful-only AI assistant. These initial responses will typically be quite harmful and toxic.
2: Ask the model to critique its response according to a principle in the constitution, and then revise the original response in light of the critique. Revise responses repeatedly in a sequence, where we randomly draw principles from the constitution at each step.
3: Finetune a pre-trained language model with SL on the final revised responses. (Generated is the AI Assistant)
In Reinforcement Learning (RL) Stage Phase
(AI Comparison Evaluations → Preference Model (PM)→ Reinforcement Learning)
This stage mimics RLHF, except that RLAIF is performed, where the AI evaluates responses according to a set of constitutional principles.
1: SL-CAI assistant is used to generate a pair of responses to each prompt in a dataset of harmful prompts.
2: Formulate each prompt and pair it into a multiple-choice question, where we ask which response is best according to a constitutional principle. This produces an AI-generated preference model.
3: Train a preference model(PM) on this comparison data, following the process in, resulting in a PM that can assign a score to any given sample.
4: Finetune the SL model from the first stage via RL against this PM, to obtain the final Reinforcement Learning Constitutional AI (RL-CAI) model.
The conclusion that the authors found was RL-CAI models are significantly more harmless than the RLHF and SL-CAI models.
An example of prompt → Response → Critique → Revision:

In Simple words, my understanding of Constitutional AI, Training LLMs using the Principles:
1: Request is made
2: A response (could be a word, sentence, or paragraph) is generated
3: Generated response is passed through some guidelines, and principles and critiqued and passed through multiple revision processes
3: Final response
I have tried to put only key points here and not overwhelm you with lots of information, I might have forgotten the points, kindly point out them in the comments section. so, that someone will be benefitted from it.
For more information and read more in the paper about Constitutional AI, you can refer to Constitutional AI: Harmlessness from AI Feedback (arxiv.org)